查询性能分析
查询性能分析
查询分析的意义在于帮助用户理解查询的执行机制和性能瓶颈,从而实现查询优化和性能提升。这不仅关乎到查询的执行效率,也直接影响到应用的用户体验和资源的有效利用。为了进行有效的查询分析,IoTDB 提供了查询分析语句:Explain 和 Explain Analyze。
- Explain 语句:允许用户预览查询 SQL 的执行计划,包括 IoTDB 如何组织数据检索和处理。
- Explain Analyze 语句:在 Explain 语句基础上增加了性能分析,完整执行 SQL 并展示查询执行过程中的时间和资源消耗。为 IoTDB 用户深入理解查询详情以及进行查询优化提供了详细的相关信息。与其他常用的 IoTDB 排查手段相比,Explain Analyze 没有部署负担,同时能够针对单条 sql 进行分析,能够更好定位问题。各类方法对比如下::
| 方法 | 安装难度 | 业务影响 | 功能范围 |
|---|---|---|---|
| Explain Analyze语句 | 低。无需安装额外组件,为IoTDB内置SQL语句 | 低。只会影响当前分析的单条查询,对线上其他负载无影响 | 支持分布式,可支持对单条SQL进行追踪 |
| 监控面板 | 中。需要安装IoTDB监控面板工具,并开启IoTDB监控服务 | 中。IoTDB监控服务记录指标会带来额外耗时 | 支持分布式,仅支持对数据库整体查询负载和耗时进行分析 |
| Arthas抽样 | 中。需要安装Java Arthas工具(部分内网无法直接安装Arthas,且安装后,有时需要重启应用) | 高。CPU 抽样可能会影响线上业务的响应速度 | 不支持分布式,仅支持对数据库整体查询负载和耗时进行分析 |
1. Explain 语句
语法
Explain命令允许用户查看SQL查询的执行计划。执行计划以算子的形式展示,描述了IoTDB会如何执行查询。其语法如下,其中SELECT_STATEMENT是查询相关的SQL语句:
EXPLAIN <SELECT_STATEMENT>含义
-- 创建数据库
create database test;
-- 创建表
use test;
create table t1 (device_id STRING ID, type STRING ATTRIBUTE, speed float);
-- 插入数据
insert into t1(device_id, type, speed) values('car_1', 'Model Y', 120.0);
insert into t1(device_id, type, speed) values('car_2', 'Model 3', 100.0);
-- 执行 explain 语句
explain select * from t1;执行上方SQL,会得到如下结果。不难看出,IoTDB 分别通过两个 TableScan 节点去不同的数据分区中获取表中的数据,最后通过Collect 算子汇总数据后返回。
+-----------------------------------------------------------------------------------------------+
| distribution plan|
+-----------------------------------------------------------------------------------------------+
| ┌─────────────────────────────────────────────┐ |
| │OutputNode-4 │ |
| │OutputColumns-[time, device_id, type, speed] │ |
| │OutputSymbols: [time, device_id, type, speed]│ |
| └─────────────────────────────────────────────┘ |
| │ |
| │ |
| ┌─────────────────────────────────────────────┐ |
| │Collect-21 │ |
| │OutputSymbols: [time, device_id, type, speed]│ |
| └─────────────────────────────────────────────┘ |
| ┌───────────────────────┴───────────────────────┐ |
| │ │ |
|┌─────────────────────────────────────────────┐ ┌───────────┐ |
|│TableScan-19 │ │Exchange-28│ |
|│QualifiedTableName: test.t1 │ └───────────┘ |
|│OutputSymbols: [time, device_id, type, speed]│ │ |
|│DeviceNumber: 1 │ │ |
|│ScanOrder: ASC │ ┌─────────────────────────────────────────────┐|
|│PushDownOffset: 0 │ │TableScan-20 │|
|│PushDownLimit: 0 │ │QualifiedTableName: test.t1 │|
|│PushDownLimitToEachDevice: false │ │OutputSymbols: [time, device_id, type, speed]│|
|│RegionId: 2 │ │DeviceNumber: 1 │|
|└─────────────────────────────────────────────┘ │ScanOrder: ASC │|
| │PushDownOffset: 0 │|
| │PushDownLimit: 0 │|
| │PushDownLimitToEachDevice: false │|
| │RegionId: 1 │|
| └─────────────────────────────────────────────┘|
+-----------------------------------------------------------------------------------------------+2. Explain Analyze 语句
语法
EXPLAIN ANALYZE [VERBOSE] <SELECT_STATEMENT>其中 SELECT_STATEMENT 对应需要分析的查询语句;VERBOSE为打印详细分析结果,不填写VERBOSE时EXPLAIN ANALYZE将会省略部分信息。
含义
Explain Analyze 是 IOTDB 查询引擎自带的性能分析 SQL,与 Explain 不同,它会执行对应的查询计划并统计执行信息,可以用于追踪一条查询的具体性能分布,用于对资源进行观察,进行性能调优与异常分析。
在 EXPLAIN ANALYZE 的结果集中,会包含如下信息:
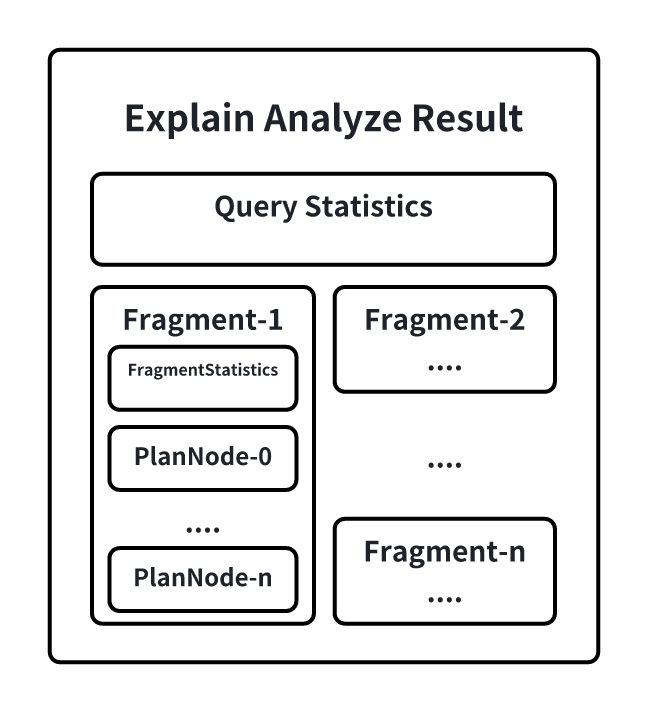
其中:
- QueryStatistics 包含查询层面进的统计信息,主要包含各规划阶段耗时,查询分片数量等信息。
- Analyze Cost: SQL 分析阶段的耗时(包含 FetchPartitionCost 和 FetchSchemaCost)
- Fetch Partition Cost:拉取分区表的耗时
- Fetch Schema Cost:拉取元数据以及权限校验的耗时
- Logical Plan Cost:构建逻辑计划的耗时
- Logical Optimization Cost: 逻辑计划优化的耗时
- Distribution Plan Cost:构建分布式计划的耗时
- Fragment Instance Count:总的查询分片的数量,每个查询分片的信息会挨个输出
- FragmentInstance 是 IoTDB 一个查询分片的封装,每一个查询分片都会在结果集中输出一份分片的执行信息,主要包含 FragmentStatistics 和算子信息。FragmentStastistics 包含 Fragment 的统计信息,包括总实际耗时(墙上时间),所涉及到的 TsFile,调度信息等情况。在一个 Fragment 的信息输出同时会以节点树层级的方式展示该Fragment 下计划节点的统计信息,主要包括:CPU运行时间、输出的数据行数、指定接口被调用的次数、所占用的内存、节点专属的定制信息。
Total Wall Time: 该分片从开始执行到执行结束的物理时间
Cost of initDataQuerySource:构建查询文件列表
Seq File(unclosed): 未封口(memtable)的顺序文件数量, Seq File(closed): 封口的顺序文件数量
UnSeq File(unclosed): 未封口(memtable)的乱序文件数量, UnSeq File(closed): 未封口的乱序文件数量
ready queued time: 查询分片的所有task在 ready queue 中的总时长(task 未阻塞,但没有查询执行线程资源时,会被放入ready queue),blocked queued time: 查询分片的所有task在 bloced queue 中的总时长(task 因为某些资源,如内存,或者上游数据未发送过来,则会被放入blocked queue)
BloomFilter 相关(用于判断某个序列在tsfile中是否存在,存储于tsfile尾部)
- loadBloomFilterFromCacheCount: 命中BloomFilterCache的次数
- loadBloomFilterFromDiskCount: 从磁盘中读取的次数
- loadBloomFilterActualIOSize: 从磁盘中读取BloomFilter时耗费的磁盘IO(单位为bytes)
- loadBloomFilterTime: 读取BloomFilter + 计算序列是否存在的总耗时(单位为ms)
TimeSeriesMetadata 相关(序列在tsfile中的索引信息,一个序列在一个tsfile中只会存储一个)
- loadTimeSeriesMetadataDiskSeqCount: 从封口的顺序文件里加载出的TimeSeriesMetadata数量
- 大部分情况下等于Seq File(closed),但如果有limit等算子,可能实际加载的数量会小于Seq File(closed)
- loadTimeSeriesMetadataDiskUnSeqCount: 从封口的乱序文件里加载出的TimeSeriesMetadata数量
- 大部分情况下等于UnSeq File(closed),但如果有limit等算子,可能实际加载的数量会小于UnSeq File(closed)
- loadTimeSeriesMetadataDiskSeqTime: 从封口的顺序文件里加载TimeSeriesMetadata的耗时
- 并不是所有的 TimeSeriesMetadata 加载都涉及磁盘 IO,有可能会命中TimeSeriesMetadataCache,直接从缓存中读取,但输出信息里并没有分开统计这两者的耗时
- loadTimeSeriesMetadataDiskUnSeqTime: 从未封口的顺序文件里加载TimeSeriesMetadata的耗时
- loadTimeSeriesMetadataFromCacheCount: 命中TimeSeriesMetadataCache的次数,注意这里对于对齐设备来讲,每个分量(包括time列,都会去单独请求Cache,所以对于对齐设备来讲,(loadTimeSeriesMetadataFromCacheCount + loadTimeSeriesMetadataFromDiskCount)= tsfile number * subSensor number(包括time列)
- loadTimeSeriesMetadataFromDiskCount: 从磁盘中读取TimeSeriesMetadata的次数,一次读取会把该设备下查询所有涉及到的分量都读出来缓存在TimeSeriesMetadataCache中
- loadTimeSeriesMetadataActualIOSize: 从磁盘中读取TimeSeriesMetadata时耗费的磁盘IO(单位为bytes)
- loadTimeSeriesMetadataDiskSeqCount: 从封口的顺序文件里加载出的TimeSeriesMetadata数量
Mods 文件相关
- TimeSeriesMetadataModificationTime: 读取mods文件花费的时间
Chunk 相关
- constructAlignedChunkReadersDiskCount: 读取已封口 tsfile 中总的 Chunk 数量
- constructAlignedChunkReadersDiskTime: 读取已封口 tsfile 中 Chunk 的总耗时(包含磁盘IO和解压缩)
- pageReadersDecodeAlignedDiskCount: 解编码已封口 tsfile 中总的 page 数量
- pageReadersDecodeAlignedDiskTime: 解编码已封口 tsfile 中 page 的总耗时
- loadChunkFromCacheCount: 命中ChunkCache的次数,注意这里对于对齐设备来讲,每个分量(包括time列,都会去单独请求Cache,所以对于对齐设备来讲,(loadChunkFromCacheCount + loadChunkFromDiskCount)= tsfile number * subSensor number(包括time列)* avg chunk number in each tsfile
- loadChunkFromDiskCount: 从磁盘中读取Chunk的次数,一次只会读取一个分量,并缓存在ChunkCache中
- loadChunkActualIOSize: 从磁盘中读取Chunk时耗费的磁盘IO(单位为bytes)
自V2.0.9起,在 FragmentInstance 中,将增加如下信息:
OutputPlanNodeId:表示sink节点对应的下游接收数据的节点,仅在sink节点中出现
sizeInBytes:表示exchange节点中接收到的TsBlock的字节(仅计算数据占用大小),仅在exchange节点中出现
tableScan节点过滤数据相关字段,仅在filter下推到tableScan中才有效,且仅在tableScan节点中出现:
- TimeSeriesIndexFilteredRows : 通过序列元数据(TimeseriesMetadata)过滤掉的数据行数
- ChunkIndexFilteredRows: 通过列块元数据(ChunkMetadata)过滤掉的数据行数
- PageIndexFilteredRows:通过页头内部(PageHeader)过滤掉的数据行数
- RowScanFilteredRows:一行行检查数据时候被过滤掉的行数(仅在带有verbose时才会展现)
特别说明
查询超时场景使用 Explain Analyze 语句:
Explain Analyze 本身是一种特殊的查询,所以当执行超时的时候,Explain Analyze 语句也无法正常返回结果。为了在查询超时的情况下也可以通过分析结果排查超时原因,Explain Analyze 提供了定时日志机制(无需用户配置),每经过一定的时间间隔会将 Explain Analyze 的当前结果以文本的形式输出到专门的日志中。当查询超时时,用户可以前往logs/log_explain_analyze.log中查看对应的日志进行排查。
日志的时间间隔基于查询的超时时间进行计算,可以保证在超时的情况下至少会有两次的结果记录。
示例
下面是Explain Analyze的一个例子:
-- 创建数据库
create database test;
-- 创建表
use test;
create table t1 (device_id STRING ID, type STRING ATTRIBUTE, speed float);
-- 插入数据
insert into t1(device_id, type, speed) values('car_1', 'Model Y', 120.0);
insert into t1(device_id, type, speed) values('car_2', 'Model 3', 100.0);
-- 执行 explain analyze 语句
explain analyze verbose select * from t1;得到输出如下:
+-----------------------------------------------------------------------------------------------+
| Explain Analyze|
+-----------------------------------------------------------------------------------------------+
|Analyze Cost: 38.860 ms |
|Fetch Partition Cost: 9.888 ms |
|Fetch Schema Cost: 54.046 ms |
|Logical Plan Cost: 10.102 ms |
|Logical Optimization Cost: 17.396 ms |
|Distribution Plan Cost: 2.508 ms |
|Dispatch Cost: 22.126 ms |
|Fragment Instances Count: 2 |
| |
|FRAGMENT-INSTANCE[Id: 20241127_090849_00009_1.2.0][IP: 0.0.0.0][DataRegion: 2][State: FINISHED]|
| Total Wall Time: 18 ms |
| Cost of initDataQuerySource: 6.153 ms |
| Seq File(unclosed): 1, Seq File(closed): 0 |
| UnSeq File(unclosed): 0, UnSeq File(closed): 0 |
| ready queued time: 0.164 ms, blocked queued time: 0.342 ms |
| Query Statistics: |
| loadBloomFilterFromCacheCount: 0 |
| loadBloomFilterFromDiskCount: 0 |
| loadBloomFilterActualIOSize: 0 |
| loadBloomFilterTime: 0.000 |
| loadTimeSeriesMetadataAlignedMemSeqCount: 1 |
| loadTimeSeriesMetadataAlignedMemSeqTime: 0.246 |
| loadTimeSeriesMetadataFromCacheCount: 0 |
| loadTimeSeriesMetadataFromDiskCount: 0 |
| loadTimeSeriesMetadataActualIOSize: 0 |
| constructAlignedChunkReadersMemCount: 1 |
| constructAlignedChunkReadersMemTime: 0.294 |
| loadChunkFromCacheCount: 0 |
| loadChunkFromDiskCount: 0 |
| loadChunkActualIOSize: 0 |
| pageReadersDecodeAlignedMemCount: 1 |
| pageReadersDecodeAlignedMemTime: 0.047 |
| [PlanNodeId 43]: IdentitySinkNode(IdentitySinkOperator) |
| CPU Time: 5.523 ms |
| output: 2 rows |
| HasNext() Called Count: 6 |
| Next() Called Count: 5 |
| Estimated Memory Size: : 327680 |
| [PlanNodeId 31]: CollectNode(CollectOperator) |
| CPU Time: 5.512 ms |
| output: 2 rows |
| HasNext() Called Count: 6 |
| Next() Called Count: 5 |
| Estimated Memory Size: : 327680 |
| [PlanNodeId 29]: TableScanNode(TableScanOperator) |
| CPU Time: 5.439 ms |
| output: 1 rows |
| HasNext() Called Count: 3
| Next() Called Count: 2 |
| Estimated Memory Size: : 327680 |
| DeviceNumber: 1 |
| CurrentDeviceIndex: 0 |
| [PlanNodeId 40]: ExchangeNode(ExchangeOperator) |
| CPU Time: 0.053 ms |
| output: 1 rows |
| HasNext() Called Count: 2 |
| Next() Called Count: 1 |
| Estimated Memory Size: : 131072 |
| |
|FRAGMENT-INSTANCE[Id: 20241127_090849_00009_1.3.0][IP: 0.0.0.0][DataRegion: 1][State: FINISHED]|
| Total Wall Time: 13 ms |
| Cost of initDataQuerySource: 5.725 ms |
| Seq File(unclosed): 1, Seq File(closed): 0 |
| UnSeq File(unclosed): 0, UnSeq File(closed): 0 |
| ready queued time: 0.118 ms, blocked queued time: 5.844 ms |
| Query Statistics: |
| loadBloomFilterFromCacheCount: 0 |
| loadBloomFilterFromDiskCount: 0 |
| loadBloomFilterActualIOSize: 0 |
| loadBloomFilterTime: 0.000 |
| loadTimeSeriesMetadataAlignedMemSeqCount: 1 |
| loadTimeSeriesMetadataAlignedMemSeqTime: 0.004 |
| loadTimeSeriesMetadataFromCacheCount: 0 |
| loadTimeSeriesMetadataFromDiskCount: 0 |
| loadTimeSeriesMetadataActualIOSize: 0 |
| constructAlignedChunkReadersMemCount: 1 |
| constructAlignedChunkReadersMemTime: 0.001 |
| loadChunkFromCacheCount: 0 |
| loadChunkFromDiskCount: 0 |
| loadChunkActualIOSize: 0 |
| pageReadersDecodeAlignedMemCount: 1 |
| pageReadersDecodeAlignedMemTime: 0.007 |
| [PlanNodeId 42]: IdentitySinkNode(IdentitySinkOperator) |
| CPU Time: 0.270 ms |
| output: 1 rows |
| HasNext() Called Count: 3 |
| Next() Called Count: 2 |
| Estimated Memory Size: : 327680 |
| [PlanNodeId 30]: TableScanNode(TableScanOperator) |
| CPU Time: 0.250 ms |
| output: 1 rows |
| HasNext() Called Count: 3 |
| Next() Called Count: 2 |
| Estimated Memory Size: : 327680 |
| DeviceNumber: 1 |
| CurrentDeviceIndex: 0 |
+-----------------------------------------------------------------------------------------------+3. 常见问题
1. WALL TIME(墙上时间)和 CPU TIME(CPU时间)的区别?
CPU 时间也称为处理器时间或处理器使用时间,指的是程序在执行过程中实际占用 CPU 进行计算的时间,显示的是程序实际消耗的处理器资源。
墙上时间也称为实际时间或物理时间,指的是从程序开始执行到程序结束的总时间,包括了所有等待时间。。
- WALL TIME < CPU TIME 的场景:比如一个查询分片最后被调度器使用两个线程并行执行,真实物理世界上是 10s 过去了,但两个线程,可能一直占了两个 cpu 核跑了 10s,那 cpu time 就是 20s,wall time就是 10s
- WALL TIME > CPU TIME 的场景:因为系统内可能会存在多个查询并行执行,但查询的执行线程数和内存是固定的,
- 所以当查询分片被某些资源阻塞住时(比如没有足够的内存进行数据传输、或等待上游数据)就会放入Blocked Queue,此时查询分片并不会占用 CPU TIME,但WALL TIME(真实物理时间的时间)是在向前流逝的
- 或者当查询线程资源不足时,比如当前共有16个查询线程,但系统内并发有20个查询分片,即使所有查询都没有被阻塞,也只会同时并行运行16个查询分片,另外四个会被放入 READY QUEUE,等待被调度执行,此时查询分片并不会占用 CPU TIME,但WALL TIME(真实物理时间的时间)是在向前流逝的
2. Explain Analyze 是否有额外开销,测出的耗时是否与查询真实执行时有差别?
几乎没有,因为 explain analyze operator 是单独的线程执行,收集原查询的统计信息,且这些统计信息,即使不explain analyze,原来的查询也会生成,只是没有人去取。并且 explain analyze 是纯 next 遍历结果集,不会打印,所以与原来查询真实执行时的耗时不会有显著差别。
3. IO 耗时主要关注几个指标?
涉及 IO 耗时的指标主要有:loadBloomFilterActualIOSize, loadBloomFilterTime, loadTimeSeriesMetadataAlignedDisk[Seq/Unseq]Time, loadTimeSeriesMetadataActualIOSize, alignedTimeSeriesMetadataModificationTime, constructAlignedChunkReadersDiskTime, loadChunkActualIOSize,各指标的具体含义见上文。
TimeSeriesMetadata 的加载分别统计了顺序和乱序文件,但 Chunk 的读取暂时未分开统计,但顺乱序比例可以通过TimeseriesMetadata 顺乱序的比例计算出来。
4. 乱序数据对查询性能的影响能否有一些指标展示出来?
乱序数据产生的影响主要有两个:
- 需要在内存中多做一个归并排序(一般认为这个耗时是比较短的,毕竟是纯内存的 cpu 操作)
- 乱序数据会产生数据块间的时间范围重叠,导致统计信息无法使用
- 无法利用统计信息直接 skip 掉整个不满足值过滤要求的 chunk
- 一般用户的查询都是只包含时间过滤条件,则不会有影响
- 无法利用统计信息直接计算出聚合值,无需读取数据
- 无法利用统计信息直接 skip 掉整个不满足值过滤要求的 chunk
单独对于乱序数据的性能影响,目前并没有有效的观测手段,除非就是在有乱序数据的时候,执行一遍查询耗时,然后等乱序合完了,再执行一遍,才能对比出来。
因为即使乱序这部分数据进了顺序,也是需要 IO、加压缩、decode,这个耗时少不了,不会因为乱序数据被合并进乱序了,就减少了。
5. 执行 explain analyze 时,查询超时后,为什么结果没有输出在 log_explain_analyze.log 中?
升级时,只替换了 lib 包,没有替换 conf/logback-datanode.xml,需要替换一下 conf/logback-datanode.xml,然后不需要重启(该文件内容可以被热加载),大约等待 1 分钟后,重新执行 explain analyze verbose。