Common Concepts
Common Concepts
1. SQL Dialect Related Concepts
1.1 sql_dialect
IoTDB supports two time-series data mode (SQL dialects), both managing devices and measurement points:
- Tree Mode: Organizes data in a hierarchical path structure, where each path represents a measurement point of a device.
- Table Mode: Organizes data in a relational table format, where each table corresponds to a type of device.
Each dialect comes with its own SQL syntax and query patterns tailored to its data mode.
1.2 Schema
Schema refers to the metadata structure of the database, which can follow either a tree or table format. It includes definitions such as measurement point names, data types, and storage configurations.
1.3 Device
A device corresponds to a physical device in a real-world scenario, typically associated with multiple measurement points.
1.4 Timeseries
Also referred to as: physical quantity, time series, timeline, point, signal, metric, measurement value, etc.
A measurement point is a time series consisting of multiple data points arranged in ascending timestamp order. It typically represents a collection point that periodically gathers physical quantities from its environment.
1.5 Encoding
Encoding is a compression technique that represents data in binary form, improving storage efficiency. IoTDB supports multiple encoding methods for different types of data. For details, refer to: Compression and Encoding 。
1.6 Compression
After encoding, IoTDB applies additional compression techniques to further reduce data size and improve storage efficiency. Various compression algorithms are supported. For details, refer to: Compression and Encoding。
2. Distributed System Related Concepts
IoTDB supports distributed deployments, typically in a 3C3D cluster model (3 ConfigNodes, 3 DataNodes), as illustrated below:
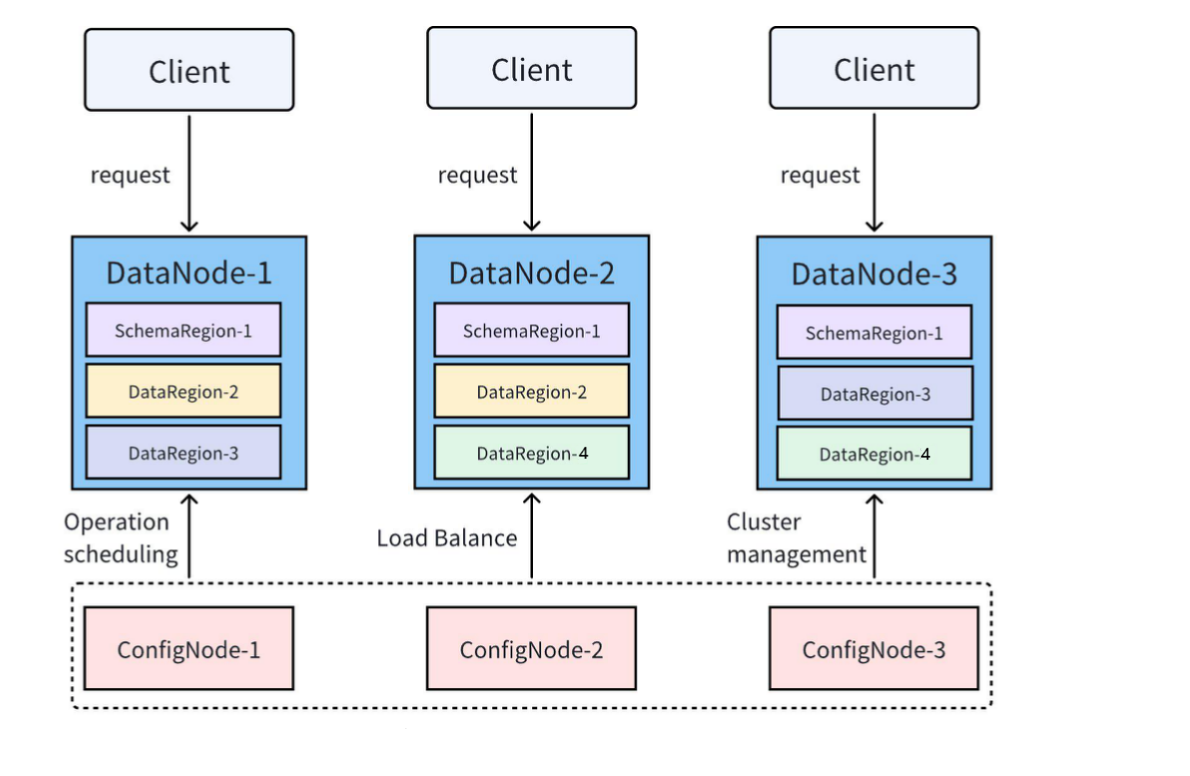
2.1 Key Concepts
- Nodes (ConfigNode, DataNode*, AINode*)
- Regions (SchemaRegion, DataRegion)
- Replica Groups
Below is an introduction to these concepts.
2.2 Nodes
An IoTDB cluster consists of three types of nodes, each with distinct responsibilities:
- ConfigNode (Management Node) Manages cluster metadata, configuration, user permissions, schema, and partitioning. It also handles distributed scheduling and load balancing. All ConfigNodes are replicated for high availability.
- DataNode (Storage and Computation Node) Handles client requests, stores data, and executes computations.
- AINode (Analytics Node) Provides machine learning capabilities, allowing users to register pre-trained models and perform inference via SQL. It includes built-in time-series mode and common ML algorithms for tasks like prediction and anomaly detection.
2.3 Data Partitioning
IoTDB divides schema and data into Regions, which are managed by DataNodes.
- SchemaRegion: Stores schema information (devices and measurement points). Regions with the same RegionID across different DataNodes serve as replicas.
- DataRegion: Stores time-series data for a subset of devices over a specified time period. Regions with the same RegionID across different DataNodes act as replicas.
For more details, see Cluster Data Partitioning
2.4 Replica Groups
Replica groups ensure high availability by maintaining multiple copies of schema and data. The recommended replication configurations are:
| Category | Configuration Item | Standalone Recommended | Cluster Recommended |
|---|---|---|---|
| Metadata | schema_replication_factor | 1 | 3 |
| Data | data_replication_factor | 1 | 2 |
3. Deployment Related Concepts
IoTDB has two operation modes: standalone mode and cluster mode.
3.1 Standalone Mode
An IoTDB standalone instance includes 1 ConfigNode and 1 DataNode, referred to as 1C1D.
- Features: Easy for developers to install and deploy, with lower deployment and maintenance costs, and convenient operation.
- Applicable scenarios: Situations with limited resources or where high availability is not a critical requirement, such as edge servers.
- Deployment method:Stand-Alone Deployment
3.2 Cluster Mode
An IoTDB cluster instance consists of 3 ConfigNodes and no fewer than 3 DataNodes, typically 3 DataNodes, referred to as 3C3D. In the event of partial node failures, the remaining nodes can still provide services, ensuring high availability of the database service, and the database performance can be improved with the addition of nodes.
- Features: High availability and scalability, with the ability to enhance system performance by adding DataNodes.
- Applicable scenarios: Enterprise-level application scenarios that require high availability and reliability.
- Deployment method: Cluster Deployment
3.3 Summary of Features
| Dimension | Stand-Alone Mode | Cluster Mode |
|---|---|---|
| Applicable Scenario | Edge deployment, low requirement for high availability | High-availability business, disaster recovery scenarios, etc. |
| Number of Machines Required | 1 | ≥3 |
| Security and Reliability | Cannot tolerate single-point failure | High, can tolerate single-point failure |
| Scalability | Scalable by adding DataNodes to improve performance | Scalable by adding DataNodes to improve performance |
| Performance | Scalable with the number of DataNodes | Scalable with the number of DataNodes |
- The deployment steps for standalone mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with the only differences being the number of replicas and the minimum number of nodes required to provide services.