CONTINUOUS QUERY(CQ)
CONTINUOUS QUERY(CQ)
1. Introduction
Continuous queries(CQ) are queries that run automatically and periodically on realtime data and store query results in other specified time series.
Users can implement sliding window streaming computing through continuous query, such as calculating the hourly average temperature of a sequence and writing it into a new sequence. Users can customize the RESAMPLE clause to create different sliding windows, which can achieve a certain degree of tolerance for out-of-order data.
2. Syntax
CREATE (CONTINUOUS QUERY | CQ) <cq_id>
[RESAMPLE
[EVERY <every_interval>]
[BOUNDARY <execution_boundary_time>]
[RANGE <start_time_offset>[, end_time_offset]]
]
[TIMEOUT POLICY BLOCKED|DISCARD]
BEGIN
SELECT CLAUSE
INTO CLAUSE
FROM CLAUSE
[WHERE CLAUSE]
[GROUP BY(<group_by_interval>[, <sliding_step>]) [, level = <level>]]
[HAVING CLAUSE]
[FILL {PREVIOUS | LINEAR | constant}]
[LIMIT rowLimit OFFSET rowOffset]
[ALIGN BY DEVICE]
ENDNote:
- If there exists any time filters in WHERE CLAUSE, IoTDB will throw an error, because IoTDB will automatically generate a time range for the query each time it's executed.
- GROUP BY TIME CLAUSE is different, it doesn't contain its original first display window parameter which is [start_time, end_time). It's still because IoTDB will automatically generate a time range for the query each time it's executed.
- If there is no group by time clause in query, EVERY clause is required, otherwise IoTDB will throw an error.
2.1 Descriptions of parameters in CQ syntax
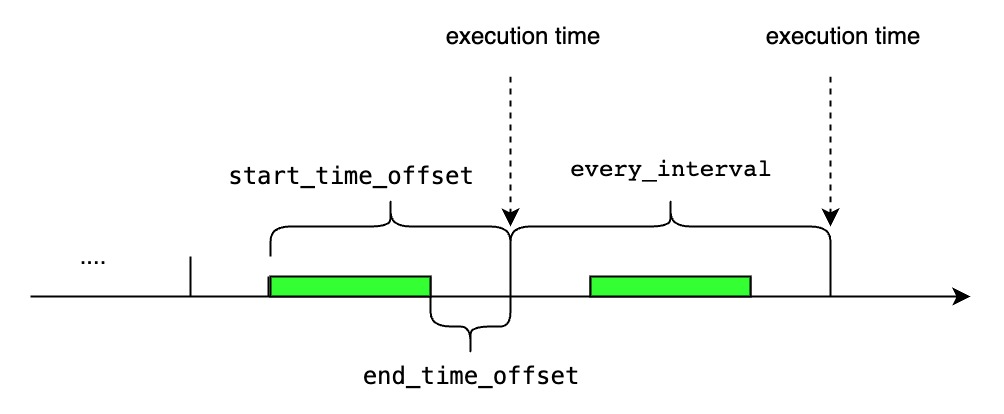
<cq_id>specifies the globally unique id of CQ.<every_interval>specifies the query execution time interval. We currently support the units of ns, us, ms, s, m, h, d, w, and its value should not be lower than the minimum threshold configured by the user, which iscontinuous_query_min_every_interval. It's an optional parameter, default value is set togroup_by_intervalin group by clause.<start_time_offset>specifies the start time of each query execution asnow()-<start_time_offset>. We currently support the units of ns, us, ms, s, m, h, d, w.It's an optional parameter, default value is set toevery_intervalin resample clause.<end_time_offset>specifies the end time of each query execution asnow()-<end_time_offset>. We currently support the units of ns, us, ms, s, m, h, d, w.It's an optional parameter, default value is set to0.<execution_boundary_time>is a date that represents the execution time of a certain cq task.<execution_boundary_time>can be earlier than, equals to, later than current time.- This parameter is optional. If not specified, it is equal to
BOUNDARY 0。 - The start time of the first time window is
<execution_boundary_time> - <start_time_offset>. - The end time of the first time window is
<execution_boundary_time> - <end_time_offset>. - The time range of the
i (1 <= i)thwindow is[<execution_boundary_time> - <start_time_offset> + (i - 1) * <every_interval>, <execution_boundary_time> - <end_time_offset> + (i - 1) * <every_interval>). - If the current time is earlier than or equal to
execution_boundary_time, then the first execution moment of the continuous query isexecution_boundary_time. - If the current time is later than
execution_boundary_time, then the first execution moment of the continuous query is the firstexecution_boundary_time + i * <every_interval>that is later than or equal to the current time .
<every_interval>,<start_time_offset>and<group_by_interval>should all be greater than0.- The value of
<group_by_interval>should be less than or equal to the value of<start_time_offset>, otherwise the system will throw an error.- Users should specify the appropriate
<start_time_offset>and<every_interval>according to actual needs.
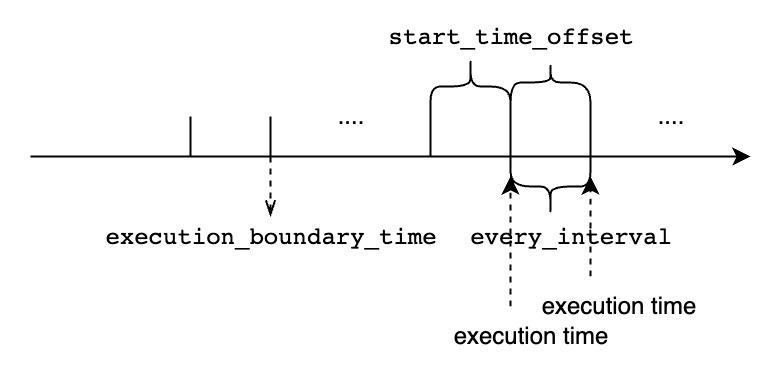
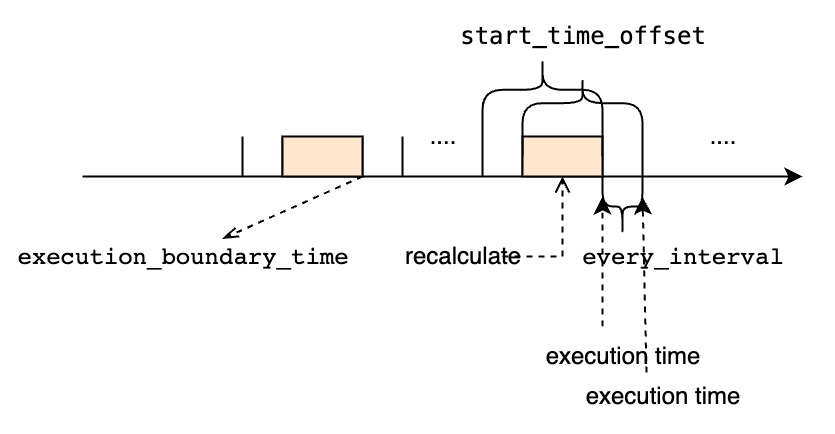
- If
<start_time_offset>is greater than<every_interval>, there will be partial data overlap in each query window.- If
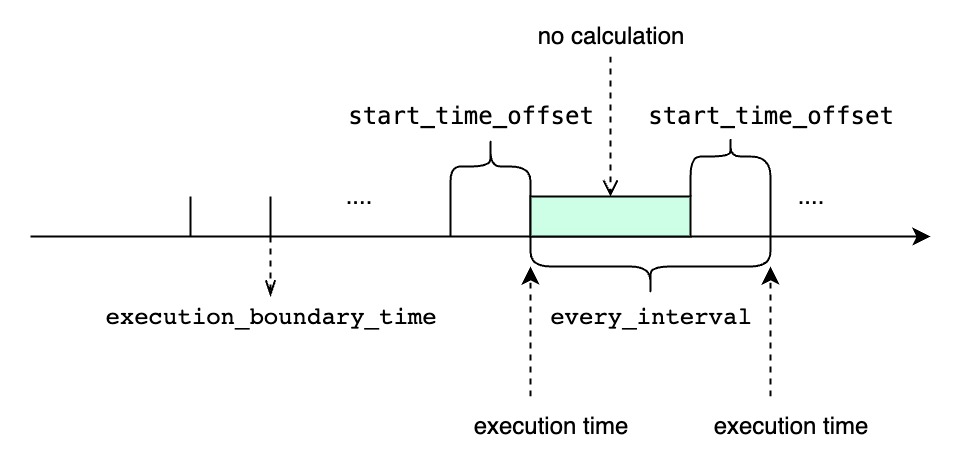
<start_time_offset>is less than<every_interval>, there may be uncovered data between each query window.start_time_offsetshould be larger thanend_time_offset, otherwise the system will throw an error.
<start_time_offset> == <every_interval>
<start_time_offset> > <every_interval>
<start_time_offset> < <every_interval>
<every_interval> is not zero
TIMEOUT POLICYspecify how we deal with the cq task whose previous time interval execution is not finished while the next execution time has reached. The default value isBLOCKED.BLOCKEDmeans that we will block and wait to do the current cq execution task until the previous time interval cq task finishes. If usingBLOCKEDpolicy, all the time intervals will be executed, but it may be behind the latest time interval.DISCARDmeans that we just discard the current cq execution task and wait for the next execution time and do the next time interval cq task. If usingDISCARDpolicy, some time intervals won't be executed when the execution time of one cq task is longer than the<every_interval>. However, once a cq task is executed, it will use the latest time interval, so it can catch up at the sacrifice of some time intervals being discarded.
3. Examples of CQ
The examples below use the following sample data. It's a real time data stream and we can assume that the data arrives on time.
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
| Time|root.ln.wf02.wt02.temperature|root.ln.wf02.wt01.temperature|root.ln.wf01.wt02.temperature|root.ln.wf01.wt01.temperature|
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
|2021-05-11T22:18:14.598+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:19.941+08:00| 0.0| 68.0| 68.0| 103.0|
|2021-05-11T22:18:24.949+08:00| 122.0| 45.0| 11.0| 14.0|
|2021-05-11T22:18:29.967+08:00| 47.0| 14.0| 59.0| 181.0|
|2021-05-11T22:18:34.979+08:00| 182.0| 113.0| 29.0| 180.0|
|2021-05-11T22:18:39.990+08:00| 42.0| 11.0| 52.0| 19.0|
|2021-05-11T22:18:44.995+08:00| 78.0| 38.0| 123.0| 52.0|
|2021-05-11T22:18:49.999+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:55.003+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+3.1 Configuring execution intervals
Use an EVERY interval in the RESAMPLE clause to specify the CQ’s execution interval, if not specific, default value is equal to group_by_interval.
CREATE CONTINUOUS QUERY cq1
RESAMPLE EVERY 20s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
ENDcq1 calculates the 10-second average of temperature sensor under the root.ln prefix path and stores the results in the temperature_max sensor using the same prefix path as the corresponding sensor.
cq1 executes at 20-second intervals, the same interval as the EVERY interval. Every 20 seconds, cq1 runs a single query that covers the time range for the current time bucket, that is, the 20-second time bucket that intersects with now().
Supposing that the current time is 2021-05-11T22:18:40.000+08:00, we can see annotated log output about cq1 running at DataNode if you set log level to DEBUG:
At **2021-05-11T22:18:40.000+08:00**, `cq1` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`.
`cq1` generate 2 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq1` executes a query within the time range `[2021-05-11T22:18:40, 2021-05-11T22:19:00)`.
`cq1` generate 2 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>cq1 won't deal with data that is before the current time window which is 2021-05-11T22:18:20.000+08:00, so here are the results:
> SELECT temperature_max from root.ln.*.*;
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+3.2 Configuring time range for resampling
Use start_time_offset in the RANGE clause to specify the start time of the CQ’s time range, if not specific, default value is equal to EVERY interval.
CREATE CONTINUOUS QUERY cq2
RESAMPLE RANGE 40s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
ENDcq2 calculates the 10-second average of temperature sensor under the root.ln prefix path and stores the results in the temperature_max sensor using the same prefix path as the corresponding sensor.
cq2 executes at 10-second intervals, the same interval as the group_by_interval. Every 10 seconds, cq2 runs a single query that covers the time range between now() minus the start_time_offset and now() , that is, the time range between 40 seconds prior to now() and now().
Supposing that the current time is 2021-05-11T22:18:40.000+08:00, we can see annotated log output about cq2 running at DataNode if you set log level to DEBUG:
At **2021-05-11T22:18:40.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:40)`.
`cq2` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| NULL| NULL| NULL| NULL|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:18:50.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:10, 2021-05-11T22:18:50)`.
`cq2` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq2` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:19:00)`.
`cq2` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>cq2 won't write lines that are all null. Notice cq2 will also calculate the results for some time interval many times. Here are the results:
> SELECT temperature_max from root.ln.*.*;
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+3.3 Configuring execution intervals and CQ time ranges
Use an EVERY interval and RANGE interval in the RESAMPLE clause to specify the CQ’s execution interval and the length of the CQ’s time range. And use fill() to change the value reported for time intervals with no data.
CREATE CONTINUOUS QUERY cq3
RESAMPLE EVERY 20s RANGE 40s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
FILL(100.0)
ENDcq3 calculates the 10-second average of temperature sensor under the root.ln prefix path and stores the results in the temperature_max sensor using the same prefix path as the corresponding sensor. Where possible, it writes the value 100.0 for time intervals with no results.
cq3 executes at 20-second intervals, the same interval as the EVERY interval. Every 20 seconds, cq3 runs a single query that covers the time range between now() minus the start_time_offset and now(), that is, the time range between 40 seconds prior to now() and now().
Supposing that the current time is 2021-05-11T22:18:40.000+08:00, we can see annotated log output about cq3 running at DataNode if you set log level to DEBUG:
At **2021-05-11T22:18:40.000+08:00**, `cq3` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:40)`.
`cq3` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq3` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:19:00)`.
`cq3` generate 4 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>Notice that cq3 will calculate the results for some time interval many times, so here are the results:
> SELECT temperature_max from root.ln.*.*;
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
|2021-05-11T22:18:40.000+08:00| 137.0| 172.0| 135.0| 193.0|
|2021-05-11T22:18:50.000+08:00| 16.0| 124.0| 183.0| 18.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+3.4 Configuring end_time_offset for CQ time range
Use an EVERY interval and RANGE interval in the RESAMPLE clause to specify the CQ’s execution interval and the length of the CQ’s time range. And use fill() to change the value reported for time intervals with no data.
CREATE CONTINUOUS QUERY cq4
RESAMPLE EVERY 20s RANGE 40s, 20s
BEGIN
SELECT max_value(temperature)
INTO root.ln.wf02.wt02(temperature_max), root.ln.wf02.wt01(temperature_max), root.ln.wf01.wt02(temperature_max), root.ln.wf01.wt01(temperature_max)
FROM root.ln.*.*
GROUP BY(10s)
FILL(100.0)
ENDcq4 calculates the 10-second average of temperature sensor under the root.ln prefix path and stores the results in the temperature_max sensor using the same prefix path as the corresponding sensor. Where possible, it writes the value 100.0 for time intervals with no results.
cq4 executes at 20-second intervals, the same interval as the EVERY interval. Every 20 seconds, cq4 runs a single query that covers the time range between now() minus the start_time_offset and now() minus the end_time_offset, that is, the time range between 40 seconds prior to now() and 20 seconds prior to now().
Supposing that the current time is 2021-05-11T22:18:40.000+08:00, we can see annotated log output about cq4 running at DataNode if you set log level to DEBUG:
At **2021-05-11T22:18:40.000+08:00**, `cq4` executes a query within the time range `[2021-05-11T22:18:00, 2021-05-11T22:18:20)`.
`cq4` generate 2 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq4` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`.
`cq4` generate 2 lines:
>
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
>Notice that cq4 will calculate the results for all time intervals only once after a delay of 20 seconds, so here are the results:
> SELECT temperature_max from root.ln.*.*;
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
|2021-05-11T22:18:00.000+08:00| 100.0| 100.0| 100.0| 100.0|
|2021-05-11T22:18:10.000+08:00| 121.0| 72.0| 183.0| 115.0|
|2021-05-11T22:18:20.000+08:00| 122.0| 45.0| 59.0| 181.0|
|2021-05-11T22:18:30.000+08:00| 182.0| 113.0| 52.0| 180.0|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+3.5 CQ without group by clause
Use an EVERY interval in the RESAMPLE clause to specify the CQ’s execution interval and the length of the CQ’s time range.
CREATE CONTINUOUS QUERY cq5
RESAMPLE EVERY 20s
BEGIN
SELECT temperature + 1
INTO root.precalculated_sg.::(temperature)
FROM root.ln.*.*
align by device
ENDcq5 calculates the temperature + 1 under the root.ln prefix path and stores the results in the root.precalculated_sg database. Sensors use the same prefix path as the corresponding sensor.
cq5 executes at 20-second intervals, the same interval as the EVERY interval. Every 20 seconds, cq5 runs a single query that covers the time range for the current time bucket, that is, the 20-second time bucket that intersects with now().
Supposing that the current time is 2021-05-11T22:18:40.000+08:00, we can see annotated log output about cq5 running at DataNode if you set log level to DEBUG:
At **2021-05-11T22:18:40.000+08:00**, `cq5` executes a query within the time range `[2021-05-11T22:18:20, 2021-05-11T22:18:40)`.
`cq5` generate 16 lines:
>
+-----------------------------+-------------------------------+-----------+
| Time| Device|temperature|
+-----------------------------+-------------------------------+-----------+
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt02| 123.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt02| 48.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt02| 183.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt02| 45.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt01| 46.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt01| 15.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt01| 114.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt01| 12.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt02| 12.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt02| 60.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt02| 30.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt02| 53.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt01| 15.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt01| 182.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt01| 181.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt01| 20.0|
+-----------------------------+-------------------------------+-----------+
>
At **2021-05-11T22:19:00.000+08:00**, `cq5` executes a query within the time range `[2021-05-11T22:18:40, 2021-05-11T22:19:00)`.
`cq5` generate 12 lines:
>
+-----------------------------+-------------------------------+-----------+
| Time| Device|temperature|
+-----------------------------+-------------------------------+-----------+
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt02| 79.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt02| 138.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt02| 17.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt01| 39.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt01| 173.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt01| 125.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt02| 124.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt02| 136.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt02| 184.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt01| 53.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt01| 194.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt01| 19.0|
+-----------------------------+-------------------------------+-----------+
>cq5 won't deal with data that is before the current time window which is 2021-05-11T22:18:20.000+08:00, so here are the results:
> SELECT temperature from root.precalculated_sg.*.* align by device;
+-----------------------------+-------------------------------+-----------+
| Time| Device|temperature|
+-----------------------------+-------------------------------+-----------+
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt02| 123.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt02| 48.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt02| 183.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt02| 45.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt02| 79.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt02| 138.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt02| 17.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf02.wt01| 46.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf02.wt01| 15.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf02.wt01| 114.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf02.wt01| 12.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf02.wt01| 39.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf02.wt01| 173.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf02.wt01| 125.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt02| 12.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt02| 60.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt02| 30.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt02| 53.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt02| 124.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt02| 136.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt02| 184.0|
|2021-05-11T22:18:24.949+08:00|root.precalculated_sg.wf01.wt01| 15.0|
|2021-05-11T22:18:29.967+08:00|root.precalculated_sg.wf01.wt01| 182.0|
|2021-05-11T22:18:34.979+08:00|root.precalculated_sg.wf01.wt01| 181.0|
|2021-05-11T22:18:39.990+08:00|root.precalculated_sg.wf01.wt01| 20.0|
|2021-05-11T22:18:44.995+08:00|root.precalculated_sg.wf01.wt01| 53.0|
|2021-05-11T22:18:49.999+08:00|root.precalculated_sg.wf01.wt01| 194.0|
|2021-05-11T22:18:55.003+08:00|root.precalculated_sg.wf01.wt01| 19.0|
+-----------------------------+-------------------------------+-----------+4. CQ Management
4.1 Listing continuous queries
List every CQ on the IoTDB Cluster with:
SHOW (CONTINUOUS QUERIES | CQS)SHOW (CONTINUOUS QUERIES | CQS) order results by cq_id.
Examples
SHOW CONTINUOUS QUERIES;we will get:
| cq_id | query | state |
|---|---|---|
| s1_count_cq | CREATE CQ s1_count_cq BEGIN SELECT count(s1) INTO root.sg_count.d.count_s1 FROM root.sg.d GROUP BY(30m) END | active |
4.2 Dropping continuous queries
Drop a CQ with a specific cq_id:
DROP (CONTINUOUS QUERY | CQ) <cq_id>DROP CQ returns an empty result.
Examples
Drop the CQ named s1_count_cq:
DROP CONTINUOUS QUERY s1_count_cq;4.3 Altering continuous queries
CQs can't be altered once they're created. To change a CQ, you must DROP and reCREATE it with the updated settings.
5. CQ Use Cases
5.1 Downsampling and Data Retention
Use CQs with TTL set on database in IoTDB to mitigate storage concerns. Combine CQs and TTL to automatically downsample high precision data to a lower precision and remove the dispensable, high precision data from the database.
5.2 Recalculating expensive queries
Shorten query runtimes by pre-calculating expensive queries with CQs. Use a CQ to automatically downsample commonly-queried, high precision data to a lower precision. Queries on lower precision data require fewer resources and return faster.
Pre-calculate queries for your preferred graphing tool to accelerate the population of graphs and dashboards.
5.3 Substituting for sub-query
IoTDB does not support sub queries. We can get the same functionality by creating a CQ as a sub query and store its result into other time series and then querying from those time series again will be like doing nested sub query.
Example
IoTDB does not accept the following query with a nested sub query. The query calculates the average number of non-null values of s1 at 30 minute intervals:
SELECT avg(count_s1) from (select count(s1) as count_s1 from root.sg.d group by([0, now()), 30m));To get the same results:
Create a CQ
This step performs the nested sub query in from clause of the query above. The following CQ automatically calculates the number of non-null values of s1 at 30 minute intervals and writes those counts into the new root.sg_count.d.count_s1 time series.
CREATE CQ s1_count_cq
BEGIN
SELECT count(s1)
INTO root.sg_count.d(count_s1)
FROM root.sg.d
GROUP BY(30m)
ENDQuery the CQ results
Next step performs the avg([...]) part of the outer query above.
Query the data in the time series root.sg_count.d.count_s1 to calculate the average of it:
SELECT avg(count_s1) from root.sg_count.d;6. System Parameter Configuration
| Name | Description | Data Type | Default Value |
|---|---|---|---|
continuous_query_submit_thread_count | The number of threads in the scheduled thread pool that submit continuous query tasks periodically | int32 | 2 |
continuous_query_min_every_interval_in_ms | The minimum value of the continuous query execution time interval | duration | 1000 |